Text files have to be in the 'ASCII English text' encoding. Make sure your submission follows that (issue the 'file' command on your submission before submitting it to verify).
The submission server will use a test script to check your submission. This test script is public, and you can access it!
For instance, say you are trying to submit exercise 1, which asks for a tar file with certain contents. You create the tar file in mysubmission.tar
$ /web/courses/cs3214//checkscripts/ex1 ./mysubmission.tar
<pre>
-----------------------------------
Your Submission was REJECTED
-----------------------------------
Reason:
Does not contain answers.txt
The content of the tar file is supposed to be
answers.txt dpipe.c
Your submitted content was reported as
dpipe.c
</pre>
First off, the reason should be apparent by now - your tar file does not contain answers.txt! If the reason is not apparent, then look at the checkscript:
vim /web/courses/cs3214//checkscripts/ex1and see what tests the script applies to your code.
The test scripts aren't perfect, but if the mistakes lies with us, we will own up to it. You are expected to make a reasonable effort to diagnose the problem yourself first. In the majority of cases, you did not follow the instructions in the handout.
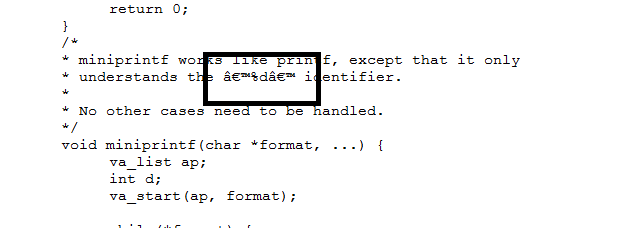
A common mistake is to create files that use Unicode characters in UTF-8 encoding. For instance, some editors convert the ASCII apostrophe into the Unicode single right quotation mark. Many editors and terminal emulators cannot properly display them, leading to garbled characters as shown here and here.
Take a look at this file to see the difference: utf8.c (if your browser displays UTF-8 characters correctly!) Please avoid using Unicode quotation marks or other Unicode characters. If your editor produces them, configure it to not to or use another editor.
Please note that I didn't dust off ancient software to show you these problems. They were obtained on a computer freshly installed with Win7 and Cygwin in 2010 (the machine I happened to use then.) Further, note that the problem is not merely cosmetic. Any Unicode-unaware program that assumes that a file consists of 8-bit characters will be unable to process these files. Even in those programs that are aware, bugs abound. Lastly, keep in mind that under the "a file is sequence of bytes" paradigm, there is no sure way to look at a file and tell what encoding it is in - only heuristics. (That's why, for instance, encoding information is transmitted outside the file/object when transmitting files across the web, HTML5's meta charset hack not withstanding).
Update 2014: Situation still has not changed. Perhaps in a future year we will default to submissions in Unicode using UTF-8 encoding as the default submission format, but I'm not holding my breath.
In a Unix environment, you may try setting the LANG environment variable to C instead of en_US (before starting your editor).
You can change it to C by adding
export LANG=C
to your .bashrc file. This way, gcc will not print Unicode left/right quotes in
its error messages.
Question:
Sorry to bother you with yet another e-mail but the submission system keeps
rejecting my file. I have been trying to submit my file for the a while now and
it's not letting me. I typed my solution in notepad++ with the correct
encoding. I tried to switch to notepad but it's still not taking
it.
Here's how I track such problems down:
First, run 'file' yourself:
$ file Exercise\ 4.txt Exercise 4.txt: Unicode text, UTF-8(Note the \ is to escape the 'space' in the filename, inserted when using the shell's auto-completion.)
$ vi Exercise\ 4.txt :set nobomb :wqand you're done:
$ file Exercise\ 4.txt Exercise 4.txt: ASCII English textI've shown the command line way of dealing with this. You can, of course, simply turn off the BOM in your editor (such as Notepad++); and instead of od, iconv, etc. etc. you can probably use Windows tools as well.
Lastly, note that 'iconv' with 'iconv --from=ascii --to=ascii' can be used to quickly find out at which offset in a file a non-ASCII character occurs (if you managed to insert one into your files.)
{kind=link}
{kind=link}