Project 2 Performance Optimization Hints§
Once you get the functionality of your p2 working, some of you will want to optimize their threadpool’s performance to earn performance points. Here are some hints. Please don’t try any of those until after you have a solid implementation that doesn’t crash or deadlock even when stress tested.
For a well-functioning threadpool, you will want to avoid frequent trips to the
kernel. While running a benchmark, you can observe its CPU utilization. Below is an
image from htop when fib_test was run with ./fib_test -n 64 41 using a threadpool that
didn’t work well
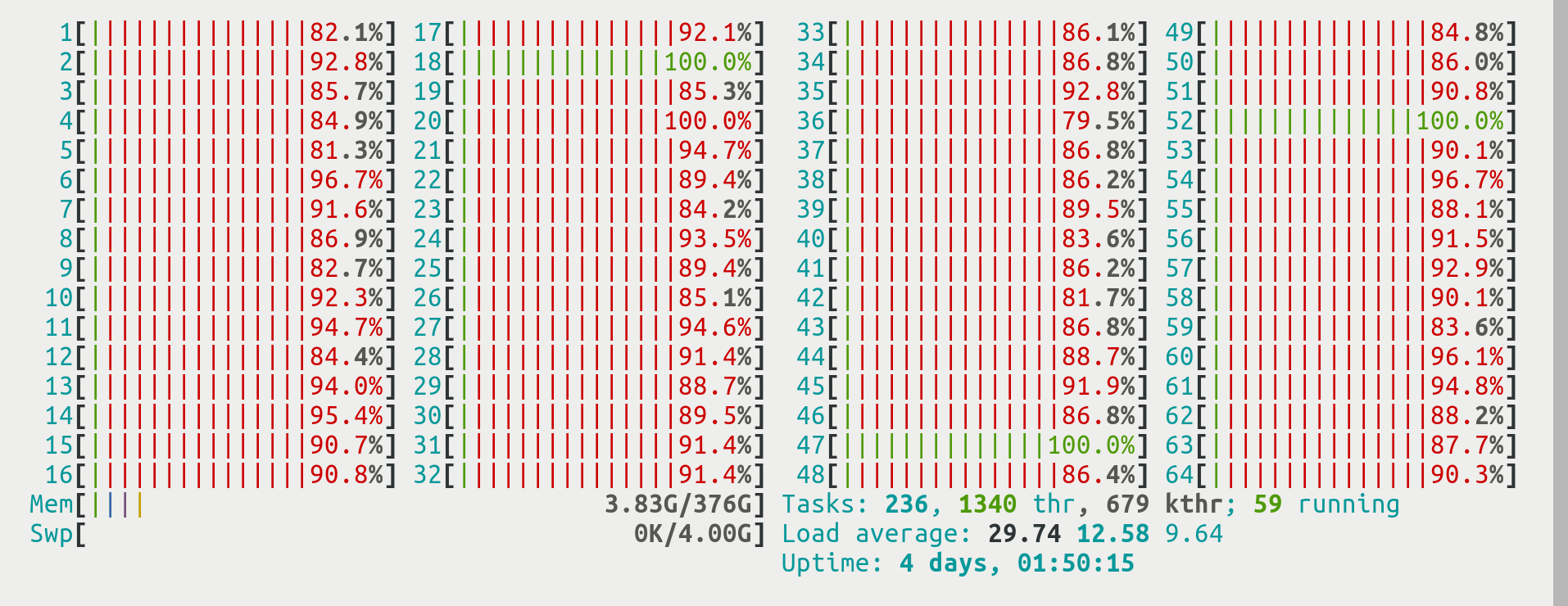
we can see all CPUs/cores in use (with a thread in the RUNNING state)
but the red color shows that the CPU spends most of its time inside the
kernel. (What you want to see is all cores lighting up in green.)
Here is a cookbook to follow:
-
Verify that all workers are indeed busy. If
htoptells you that not allnworkers are keeping a core busy, you have a signaling problem - there are tasks, but your workers are not notified. Inhtop, you would specifically see fewer cores "light up" than the-n <number of threads>argument specified for the larger benchmarks like quicksort, mergesort, or fibonacci.You can verify this in gdb - bring your code in this situation, then break (with Ctrl-C) and figure out what your workers are doing (with
thread apply all backtrace). You need to accomplish this task first. -
Avoid frequent trips to the kernel. You can identify this situation if you see all or mostly red in htop, as well as when you run under the bash built-in
time ...and an significant amount of time is reported in thesyscolumn. In our benchmarks, the only functions that make system calls are thepthread_functions: mutex lock and unlock, and cond wait and signal. There are (at least) 2 possible reasons:-
A contended lock. Here, lock and unlock will constantly make system calls because a lock is frequently contended. This means that threads often try to get a lock that’s already taken, forcing them to move into the
BLOCKEDstate inside the kernel. This could happen, for instance, if you used a global pool lock that you acquire and release on every call tothread_pool_submit. Your goal is to organize your locks such that in the common case a thread will be able to acquire the lock it's trying to acquire immediately, withoutBLOCKING. -
A frequently waited-on condition variable. Condition variables’ signal function will not go into the kernel if no thread is waiting - they’ll be, more or less, a no-op. But if you inadvertently write logic where one of your workers frequently returns to the point where they wait on a condition variable, the call to
pthread_cond_signalcan cause system calls. This could happen, for instance, if you tried to steal one task at a time, then used the condition variable to wait for more tasks. (Instead, try to steal as long as you can, and only wait when you’re certain that there’s nothing to steal.)
-
-
Avoid true sharing (pointed out in the handout already). Any design that uses a per-pool semaphore, or something like a global task counter to count the tasks submitted to the pool, exhibits a shared variable that is accessed by multiple threads on the hot path. It must be either atomic, or be protected with a lock. (This lock would be highly contended.) In either case, your performance will tank because of the cache coherency traffic this approach causes.
-
Avoid false sharing (don’t locate structs accessed by different workers in the same cache line, add appropriate padding). In fact, if you want, you can use the
offsetofmacro in<stddef.h>to check the alignment of your struct’s fields, along withsizeofto get their sizes. Experiment with different orders for the frequently accessed fields, try to keep structs in the same cache line. If your design uses single, continuously allocated worker array to hold the worker structs, be sure to add padding. -
Investigate pinning. Normally, the OS will migrate threads between CPU cores at will as part of its load balancing. If you pin a thread to a core, it won’t. Run
lscpu -a --extendedto see the CPU topology. It’s optimal (leads to the least amount of shared hardware resources) to pin threads from 0, 1, ... up to the number of CPUs in the system, which you get withsysconf(_SC_NPROCESSORS_ONLN);Use the non-portable GNU extension functionpthread_attr_set_affinity_npfor pinning.